Java HashMap 和 HashTable
HashMap 常见问题
影响 HashMap 性能的重要参数
初始容量:创建哈希表(数组)时桶的数量,默认为 16。例如负载因子为 0.75,Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
负载因子(加载因子):哈希表在其容量自动增加之前可以达到多满的一种尺度,默认为 0.75。loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据 entry 也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据 entry 也就越少,也就越稀疏。loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。
put() 的工作原理

底层数组长度为何总是2的n次方
HashMap 根据用户传入的初始化容量,利用无符号右移和按位或运算等方式计算出第一个大于该数的2的幂。
取余 % 操作中如果除数是 2 的幂次则等价于与其除数减一的与 & 操作(也就是说 hash % length == hash & ( length - 1) 的前提是 length 是 2 的 n 次方)。” 并且 采用二进制位操作 &,相对于 % 能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
1.8中做了哪些优化?
- 数组 + 链表改成了数组 + 链表或红黑树
- 链表的插入方式从头插法改成了尾插法
- 扩容的时候 1.7 需要对原数组中的元素进行重新 hash 定位在新数组的位置,1.8 采用更简单的判断逻辑,位置不变或索引 + 旧容量大小;
- 在插入时,1.7 先判断是否需要扩容,再插入,1.8 先进行插入,插入完成再判断是否需要扩容;
为什么从头插改成尾插
1、JDK 1.7 采用头插法来添加链表元素,存在链表成环的问题(数组扩容时),1.8 中做了优化,采用尾插法来添加链表元素 2、HashMap 不管在哪个版本都不是线程安全的,出了并发问题不要怪 HashMap,从自己身上找原因
最开始使用头插法(1.7)是因为缓存的时间局部性原则,最近访问过的数据下次大概率会再次访问,把刚访问过的元素放在链表最前面可以直接被查询到,减少查找次数
既然头插法有链表成环的问题,为什么直到 1.8 才采用尾插法来替代头插法?
只有在并发情况下,头插法才会出现链表成环的问题,多线程情况下,HashMap 本就非线程安全,这就相当于你在它的规则之外出了问题,那能怪谁?
既然 1.8 没有链表成环的问题,那是不是说明可以把 1.8 中的 HashMap 用在多线程中?
链表成环只是并发问题中的一种,1.8 虽然解决了此问题,但是还是会有很多其他的并发问题,比如:上秒 put 的值,下秒 get 的时候却不是刚 put 的值;因为操作都没有加锁,不是线程安全的
为什么1.8改用红黑树
比如某些人通过找到你的 hash 碰撞值,来让你的 HashMap 不断地产生碰撞,那么相同 key 位置的链表就会不断增长,当你需要对这个 HashMap 的相应位置进行查询的时候,就会去循环遍历这个超级大的链表,性能及其地下。java8使用红黑树来替代超过8个节点数的链表后,查询方式性能得到了很好的提升,从原来的是O(n)到O(logn)。(链表长度为 8 时变成红黑树)
线程安全方面会出现什么问题
在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失。 在jdk1.8中,在多线程环境下,会发生数据覆盖的情况
以下是解释:
1.put 的时候导致的多线程数据不一致
比如有两个线程A和B,首先A希望插入一个 key-value 对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
2.resize 而引起死循环
这种情况发生在 HashMap 自动扩容时,当2个线程同时检测到元素个数超过 数组大小 * 负载因子。此时2个线程会在 put() 方法中调用了 resize(),两个线程同时修改一个链表结构会产生一个循环链表(JDK1.7中,会出现resize前后元素顺序倒置的情况)。接下来再想通过 get() 获取某一个元素,就会出现死循环。
那么为什么默认是16呢?怎么不是4?不是8?
关于这个默认容量的选择,JDK并没有给出官方解释,那么这应该就是个经验值,既然一定要设置一个默认的 2^n 作为初始值,那么就需要在效率和内存使用上做一个权衡。这个值既不能太小,也不能太大。
太小了就有可能频繁发生扩容,影响效率。太大了又浪费空间,不划算。
所以,16就作为一个经验值被采用了。
HashMap 的基本使用
HashMap 顾名思义,通过哈希算法实现的(散列算法),将数据 依特定算法直接指定到一个地址上。这样一来,当集合要添加新的元素时,先调用这个元素的 HashCode 方法,就一下子能定位到它应该放置的物理位置上。
从 Object 角度看,JVM 每 new 一个 Object,它都会将这个 Object 丢到一个 Hash 表中去,这样的话,下次做 Object 的比较或者取这个对象的时候(读取过程),它会根据对象的 HashCode 再从 Hash 表中取这个对象。这样做的目的是提高取对象的效率。
具体的实现原理看 Hash 那篇笔记
这里介绍一下使用方式
// 引入 HashMap 类
public class Test {
public static void main(String[] args) {
// 创建 HashMap 对象 Sites
HashMap<Integer, String> Sites = new HashMap<Integer, String>();
// 添加键值对
Sites.put(1, "Google");
Sites.put(2, "alsritter");
Sites.put(3, "Baidu");
// 取得元素数量
System.out.println(Sites.size());
// 访问元素
System.out.println(Sites.get(3));
// 删除元素
Sites.remove(3);
// 删除全部
Sites.clear();
}
}
常用方法
| 方法 | 描述 |
|---|---|
| clear() | 删除 hashMap 中的所有键/值对 |
| clone() | 复制一份 hashMap |
| isEmpty() | 判断 hashMap 是否为空 |
| size() | 计算 hashMap 中键/值对的数量 |
| put() | 将键/值对添加到 hashMap 中 |
| putAll() | 将所有键/值对添加到 hashMap 中 |
| putIfAbsent() | 如果 hashMap 中不存在指定的键,则将指定的键/值对插入到 hashMap 中。 |
| remove() | 删除 hashMap 中指定键 key 的映射关系 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系。 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace() | 替换 hashMap 中是指定的 key 对应的 value。 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。 |
| get() | 获取指定 key 对应对 value |
| getOrDefault() | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| forEach() | 对 hashMap 中的每个映射执行指定的操作。 |
| entrySet() | 返回 hashMap 中所有映射项的集合集合视图。 |
| keySet() | 返回 hashMap 中所有 key 组成的集合视图。 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
| merge() | 添加键值对到 hashMap 中 |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hasMap 中 |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中。 |
遍历 HashMap
可以使用 for-each 来迭代 HashMap 中的元素。(毕竟也实现了 iterator)
HashMap 的遍历方式,通常有以下几种:
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, Integer> next = entryIterator.next();
System.out.println("key=" + next.getKey() + " value=" + next.getValue());
}
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
String key = iterator.next();
System.out.println("key=" + key + " value=" + map.get(key));
}
强烈建议使用第一种 EntrySet 进行遍历。
第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低。
Java 中的 HashCode
HashCode 优化 Set插入
Java 中的集合有两类,一类是 List,再有一类是 Set。前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。 equals 方法可用于保证元素不重复,但如果每增加一个元素就检查一次,若集合中现在已经有 1000 个元素,那么第 1001 个元素加入集合时,就要调用 1000 次 equals 方法。这显然会大大降低效率。 于是,HashSet 采用了哈希表的原理。
哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。这样一来,当集合要添加新的元素时,先调用这个元素的 HashCode 方法,就一下子能定位到它应该放置的物理位置上。
- 如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;
- 如果这个位置上已经有元素了,就调用它的 equals 方法与新元素进行比较,相同的话就不存了;
- 不相同的话,也就是发生了 Hash key 相同导致冲突的情况,那么就在这个 Hash key 的地方产生一个链表,将所有产生相同 HashCode 的对象放到这个单链表上去,串在一起。这样一来实际调用 equals 方法的次数就大大降低了,几乎只需要一两次。
从 Object 角度看,JVM 每 new 一个 Object,它都会将这个 Object 丢到一个 Hash 表中去,这样的话,下次做 Object 的比较或者取这个对象的时候(读取过程),它会根据对象的 HashCode 再从 Hash 表中取这个对象。这样做的目的是提高取对象的效率。若 HashCode 相同再去调用 equals
如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用
equals()来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
为何要重写 HashCode 方法
为什么重写 Object 的 equals(Object obj) 方法尽量要重写 Object 的 HashCode() 方法?
前面说了 Set 是先通过比对对象的 HashCode 来判断这些对象是否是同一个,所以如果不重写 HashCode 会导致相同的对象(内部数据相同)得到的 HashCode 也不同,从而导致 Set 里面存在重复的元素
// 自己定义一个 HashCodeClass 不重写 HashCode 方法
public class HashCodeClass {
private String str0;
private double dou0;
private int int0;
@Override
public boolean equals(Object obj) {
if (obj instanceof HashCodeClass) {
HashCodeClass hcc = (HashCodeClass)obj;
if (hcc.str0.equals(this.str0) &&
hcc.dou0 == this.dou0 &&
hcc.int0 == this.int0) {
return true;
}
return false;
}
return false;
}
}
如果不重写 HashCode() 那每个对象输出的 HashCode 都是不同的
public class TestMain
{
public static void main(String[] args)
{
System.out.println(new HashCodeClass().HashCode());
System.out.println(new HashCodeClass().HashCode());
System.out.println(new HashCodeClass().HashCode());
System.out.println(new HashCodeClass().HashCode());
System.out.println(new HashCodeClass().HashCode());
System.out.println(new HashCodeClass().HashCode());
}
}
// 如上,实例化后未赋值,按理它们应该是相同的,但是输出的 HashCode 却不相同
1901116749
1807500377
355165777
1414159026
1569228633
778966024
上面的 HashCodeClass 都没有赋初值,那么这 6 个 HashCodeClass 应该是全部相同的。
所以应该加上这个
@Override
public int hashCode() {
return Objects.hash(str0, dou0, int0);
}
HashCode 的冲突问题
为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?
因为 hashCode() 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode。
如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
JDK1.7 中的实现
1.7 中的数据结构图:
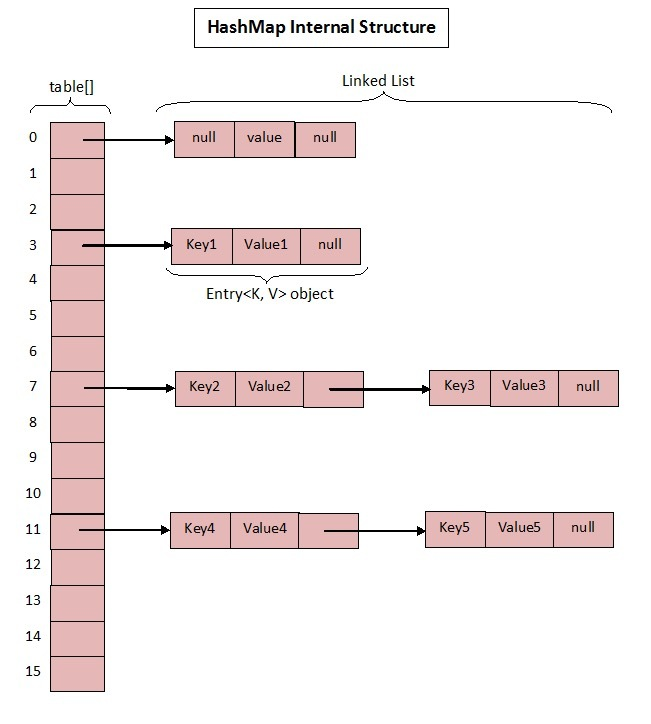
先来看看 1.7 中的实现。
核心的成员变量(默认参数)
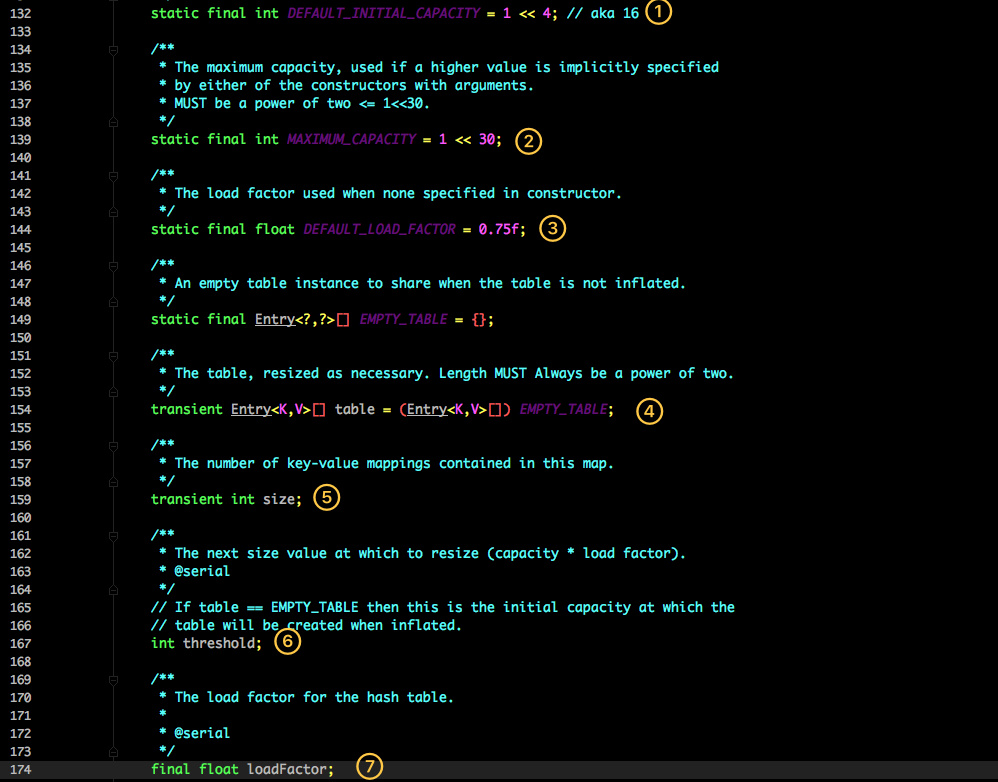
这是 HashMap 中比较核心的几个成员变量;看看分别是什么意思?
- 初始化桶大小,因为底层是数组,所以这是数组默认的大小。
- 桶最大值。
- 默认的负载因子(0.75)
- table 真正存放数据的数组。
- Map 存放数量的大小。
- 桶大小,可在初始化时显式指定。
- 负载因子,可在初始化时显式指定。
重点解释下负载因子:
由于给定的 HashMap 的容量大小是固定的,比如默认初始化:
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
因此通常建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。
根据代码可以看到其实真正存放数据的是
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
这个数组,那么它又是如何定义的呢?
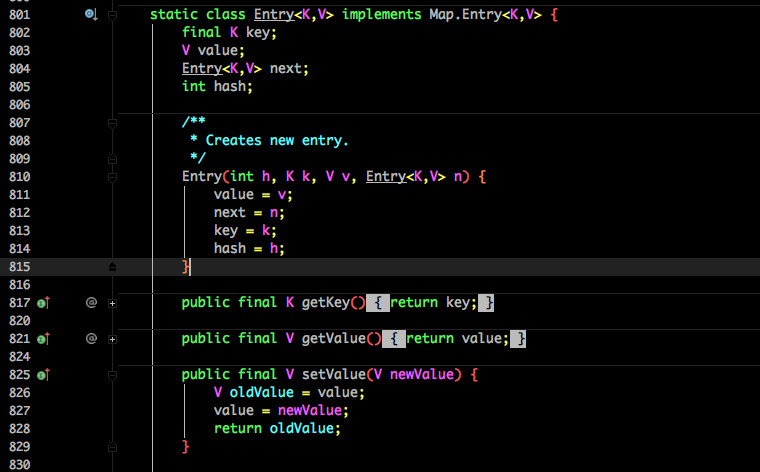
Entry 是 HashMap 中的一个内部类,从他的成员变量很容易看出:
- key 就是写入时的键。
- value 自然就是值。
- 开始的时候就提到 HashMap 是由数组和链表组成,所以这个 next 就是用于实现链表结构。
- hash 存放的是当前 key 的 hashcode。
知晓了基本结构,那来看看其中重要的写入、获取函数:
put 方法
public V put(K key, V value) {
// 判断当前数组是否需要初始化。
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 如果 key 为空,则 put 一个空值进去。
if (key == null)
return putForNullKey(value);
// 根据 key 计算出 hashcode。
int hash = hash(key);
// 根据计算出的 hashcode 定位出所在桶。
int i = indexFor(hash, table.length);
// 如果桶是一个链表则需要遍历判断里面的 hashcode、key 是否和传入 key 相等,如果相等则进行覆盖,并返回原来的值。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。
addEntry(hash, key, value, i);
return null;
}
下面介绍下这几个用到的方法
void addEntry(int hash, K key, V value, int bucketIndex) {
// 当调用 addEntry 写入 Entry 时需要判断是否需要扩容。
if ((size >= threshold) && (null != table[bucketIndex])) {
// 如果需要就进行两倍扩充,并将当前的 key 重新 hash 并定位。
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
// 而在 createEntry 中会将当前位置的桶传入到新建的桶中,如果当前桶有值就会在位置形成链表。
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
get 方法
再来看看 get 函数:
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
// 首先也是根据 key 计算出 hashcode,然后定位到具体的桶中。
int hash = (key == null) ? 0 : hash(key);
// 判断该位置是否为链表。
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
// 不是链表就根据 key、key 的 hashcode 是否相等来返回值。
if (e.hash == hash &&
// 为链表则需要遍历直到 key 及 hashcode 相等时候就返回值。
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
// 啥都没取到就直接返回 null 。
return null;
}
并发场景的死循环问题
但是 HashMap 原有的问题也都存在,比如在并发场景下使用时容易出现死循环。
如下示例:
final HashMap<String, String> map = new HashMap<String, String>();
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}).start();
}
但是为什么呢?简单分析下。
看过上文的还记得在 HashMap 扩容的时候会调用 resize() 方法,就是这里的并发操作容易在一个桶上形成环形链表;这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标就会出现死循环。
如下图:

不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
JDK1.8 中的实现
不知道 1.7 的实现大家看出需要优化的点没有?
其实一个很明显的地方就是:
当 Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为 。
因此 1.8 中重点优化了这个查询效率。
1.8 HashMap 结构图:
核心的成员变量(默认参数)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
和 1.7 大体上都差不多,还是有几个重要的区别:
- TREEIFY_THRESHOLD 用于判断是否需要将链表转换为红黑树的阈值。
- HashEntry 修改为 Node。
- Node 的核心组成其实也是和 1.7 中的 HashEntry 一样,存放的都是 key value hashcode next 等数据。
HashMap 的主干是一个 Entry 数组(哈希桶数组)。Entry 是 HashMap 的基本组成单元(JDK8 改名为 Node了),每一个 Entry 包含一个 key-value 键值对。
// HashMap 的主干数组,可以看到就是一个 Node 数组,初始值为空数组{}
transient Node<K,V>[] table;
主干数组的长度一定是 2 的次幂
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //对 key 的 hashcode 值进行 hash 运算后得到的值,存储在 Entry,避免重复计算
final K key;
V value;
Node<K,V> next; // 存储指向下一个Entry的引用,单链表结构
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
/* ... */
}
再来看看核心方法。
put 方法
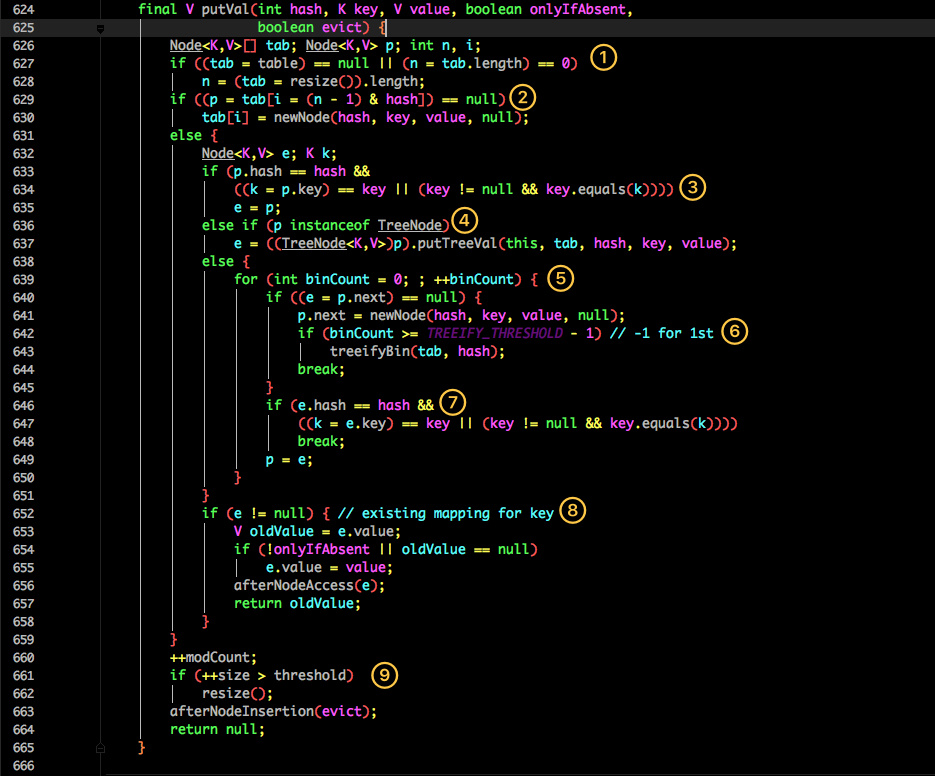
看似要比 1.7 的复杂,我们一步步拆解:
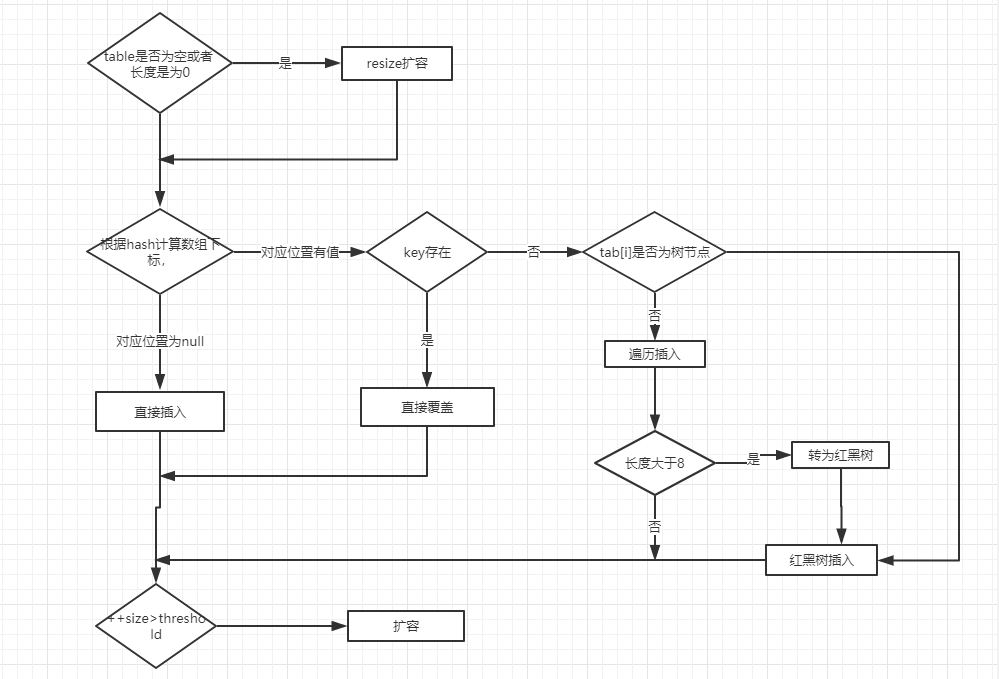
- 判断当前桶是否为空,空的就需要初始化(resize 中会判断是否进行初始化)。
- 根据当前 key 的 hashcode 定位到具体的桶中并判断是否为空,为空表明没有 Hash 冲突就直接在当前位置创建一个新桶即可。
- 如果当前桶有值(Hash 冲突),那么就要比较当前桶中的 key、key 的 hashcode 与写入的 key 是否相等,相等就赋值给 e,在第 8 步的时候会统一进行赋值及返回。
- 如果当前桶为红黑树,那就要按照红黑树的方式写入数据。
- 如果是个链表,就需要将当前的 key、value 封装成一个新节点写入到当前桶的后面(形成链表)。
- 接着判断当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树。
- 如果在遍历过程中找到 key 相同时直接退出遍历。
- 如果 e != null 就相当于存在相同的 key,那就需要将值覆盖。
- 最后判断是否需要进行扩容。
整个流程如下图所示:
get 方法
get 方法看起来就要简单许多了。
public V get(Object key) {
Node<K,V> e;
// 首先将 key hash 之后取得所定位的桶。
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 如果桶为空则直接返回 null 。
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 如果第一个不匹配,则判断它的下一个是红黑树还是链表。
if ((e = first.next) != null) {
// 红黑树就按照树的查找方式返回值。
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 不然就按照链表的方式遍历匹配返回值。
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
从这两个核心方法(get/put)可以看出 1.8 中对大链表做了优化,修改为红黑树之后查询效率直接提高到了 。
resize 方法
进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // 初始容量设置为 threshold
newCap = oldThr;
else {
// signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的 resize 上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个 bucket 都移动到新的 buckets 中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap 实现原理
如何初始化 HashMap
先来看几个重要的字段,在初始化 HashMap 时会用到这些字段
// 实际存储的 key-value 键值对的个数
transient int size;
/**
* threshold 就是阈值,当 table == {} 时,该值为初始容量(初始容量默认为16);当 table 被填充了,
* 也就是为 table 分配内存空间后,threshold 一般为 capacity*loadFactory。
* HashMap 在进行扩容时需要参考 threshold
*/
int threshold;
// 负载因子,代表了 table 的填充度有多少,默认是 0.75
final float loadFactor;
/**
* 用于快速失败,由于 HashMap 非线程安全,在对 HashMap 进行迭代时,
* 如果期间其他线程的参与导致 HashMap 的结构发生变化了(比如put,remove等操作),
* 需要抛出异常 ConcurrentModificationException
*/
transient int modCount;
HashMap 有 4个构造器,其他构造器如果用户没有传入 initialCapacity(初始容量)和 loadFactor 这两个参数,会使用默认值,初始容量为 16,loadFactor 为 0.75
public HashMap() {
// 这个 DEFAULT_LOAD_FACTOR 为 0.75
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
如果手动构建一个 HashMap 还是有所限制的(这里使用 JDK8 的代码)
// 此处对传入的初始容量进行校验,最大不能超过 MAXIMUM_CAPACITY = 1<<30(230)
public HashMap(int initialCapacity, float loadFactor) {
// 健壮性判断
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
// JDK7 中这里的 this.threshold = initialCapacity;分配两倍大小的幂是放在 put初始化那里执行的
this.threshold = tableSizeFor(initialCapacity);
}
// 对于给定的目标容量,返回两倍大小的幂。
static final int tableSizeFor(int cap) {
int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1);
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
如果没有手动指定初始容量,那数组 table 只有在第一个 put 方法调用时才会被构建,所以接下去看下面的 put 方法
loadFactor 加载因子
loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据 entry 也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据 entry 也就越少,也就越稀疏。
loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
threshold 扩容阈值
threshold = capacity * loadFactor,当 Size>=threshold 的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准。
如何添加一个元素
JDK8 之后因为当冲突大于 8之后会转成红黑树,所以这部分 put 方法有点复杂,所以这里直接看 JDK7版的。只要知道 JDK8 会变成红黑树就行了
public V put(K key, V value) {
// 如果 table 数组为空数组 {},进行数组填充(为 table 分配实际内存空间),
// 入参为 threshold,此时 threshold 为 initialCapacity 默认是 1<<4(24=16)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 如果 key 为 null,存储位置为 table[0] 或 table[0] 的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key); // 对 key 的 hashcode 进一步计算,确保散列均匀
int i = indexFor(hash, table.length);// 获取在 table 中的实际位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
// 如果该对应数据已存在,执行覆盖操作。用新 value 替换旧 value,并返回旧 value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;// 保证并发访问时,若 HashMap 内部结构发生变化,快速响应失败
addEntry(hash, key, value, i);// 新增一个 entry
return null;
}
这里的 inflateTable 方法如下,用于为 table 分配空间
private void inflateTable(int toSize) {
// 通过 roundUpToPowerOf2(toSize) 可以确保 capacity 为大于或等于 toSize 的最接近 toSize 的二次幂,
// 比如 toSize=13,则 capacity=16;to_size=16,capacity=16;to_size=17,capacity=32.
int capacity = roundUpToPowerOf2(toSize);
// //此处为 threshold 赋值,取 capacity*loadFactor 和 MAXIMUM_CAPACITY+1 的最小值,
// capacity 一定不会超过 MAXIMUM_CAPACITY,除非 loadFactor 大于 1
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
/**
* roundUpToPowerOf2 中的这段处理使得数组长度一定为 2 的次幂,
* Integer.highestOneBit 是用来获取最左边的 bit(其他 bit 位为0)所代表的数值.
*/
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
为何 HashMap 的数组长度一定是 2 的次幂?
看下面的计算就知道了
这里补充个 JDK8 初始化 table的操作
看 JDK8的 put方法,它会在第一执行时(检查到 table 是空的),执行 resize 扩容方法,关于这个方法下面扩容那部分会讲到
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/* ... */
}
下面是 JDK8 详细的插入操作,因为有点长,不感兴趣直接跳到下一部分
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果存储元素的table为空,则进行必要字段的初始化
if ((tab = table) == null || (n = tab.length) == 0)
// 获取长度
n = (tab = resize()).length;
// 如果根据hash值获取的结点为空,则新建一个结点
// 此处 & 代替了 % (除法散列法进行散列)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 这里的p结点是根据hash值算出来对应在数组中的元素
else {
Node<K,V> e; K k;
// 如果新插入的结点和table中p结点的hash值,key值相同的话
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果是红黑树结点的话,进行红黑树插入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
// 代表这个单链表只有一个头部结点,则直接新建一个结点即可
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 链表长度大于8时,将链表转红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// 及时更新p
p = e;
}
}
// 如果存在这个映射就覆盖
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 判断是否允许覆盖,并且value是否为空
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 回调以允许LinkedHashMap后置操作
afterNodeAccess(e);
return oldValue;
}
}
// 更改操作次数
++modCount;
// 大于临界值
if (++size > threshold)
// 将数组大小设置为原来的2倍,并将原先的数组中的元素放到新数组中
// 因为有链表,红黑树之类,因此还要调整他们
resize();
// 回调以允许LinkedHashMap后置操作
afterNodeInsertion(evict);
return null;
}
如何计算 hash
上面都说了 HashMap 内部结构,但是 HashMap 的灵魂,hash 是如何计算出来的?
看上面的源码,发现调用了两个方法 hash(Object key)、indexFor(int h, int length)
int hash = hash(key); // 对 key 的 hashcode 进一步计算,确保散列均匀
int i = indexFor(hash, table.length);// 获取在 table 中的实际位置
先来看这个 indexFor 方法,它是用来计算出元素具体是存在 table 哪里
/**
* 返回数组下标
*/
static int indexFor(int h, int length) {
return h & (length-1); // 实际上相当于 h % length 取余数,但 & 计算速度更快
}
理论上散列值是一个 int 型,如果直接拿散列值作为下标访问 HashMap 主数组的话,考虑到 2 进制 32 位带符号的 int 表值范围从 -2147483648 ~ 2147483648。前后加起来大概 40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。
但问题是一个 40亿长度的数组,内存是放不下的。HashMap 扩容之前的数组初始大小才 16。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来访问数组下标。所以就需要使用到这个 indexFor 方法了
上面的 “与” 操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度 16 为例,16-1=15。2进制表示是 00000000 00000000 00001111 和某散列值做 “与” 操作如下,结果就是截取了最低的四位值。
10100101 11000100 00100101
& 00000000 00000000 00001111
----------------------------------
00000000 00000000 00000101 //高位全部归零,只保留末四位
这也正好解释了为什么 HashMap 的数组长度要取 2 的整次幂。
hashMap 的数组长度一定保持 2 的次幂,比如 16 的二进制表示为 10000,那么 length-1 就是 15,二进制为 01111,同理扩容后的数组长度为 32,二进制表示为 100000,length-1 为 31,二进制表示为 011111。这样会保证低位全为 1
长度为什么是 2 的幂次方
上文可知为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。Hash 值的范围值 -2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。
所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是 (n - 1) & hash 。(n 代表数组长度)。
这个算法应该如何设计呢?(上文也讲了计算过程)
我们首先可能会想到采用 % 取余的操作来实现。但是,重点来了:“取余 % 操作中如果除数是 2 的幂次则等价于与其除数减一的与 & 操作(也就是说 hash % length == hash & ( length - 1) 的前提是 length 是 2 的 n 次方)。” 并且 采用二进制位操作 &,相对于 % 能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
为什么需要使用 “扰动函数”
上面看着只采用 hashCode,也能取得 table 里面的位置啊为什么还需要执行 hash 方法取得一个新的 hashCode?
因为上面调用的是 Object 里面的 hashCode 取得的散列码,所以为了防止一些实现比较差的 hashCode() 方法,使用扰动函数之后可以减少碰撞,进一步降低 hash 冲突的几率。
打个比方, 当我们的数组长度 n 为 16 的时候,哈希码(字符串 “abcabcabcabcabc” 的 key 对应的哈希码)对 16-1 与操作,对于多个 key 生成的 hashCode,只要哈希码的后 4 位为 0,不论不论高位怎么变化,最终的结果均为0。如下表所示
| 对象 | 二进制码 |
|---|---|
| 1954974080(HashCode) | 111 0100 1000 0110 1000 1001 1000 0000 |
| 2^4-1=15(length-1) | 000 0000 0000 0000 0000 0000 0000 1111 |
| &运算 | 000 0000 0000 0000 0000 0000 0000 0000 |
所以就需要使用 “扰动函数” 对原 HashCode 进行扰动
// 这里是 JDK8的
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
右位移 16位,正好是 32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。(如下流程图)

回到上面的例子,加上高 16位异或低 16位的“扰动函数”后,结果如下:
| 对象 | 转换成十进制 | 二进制码 |
|---|---|---|
| 原HashCode | 1954974080 | 111 0100 1000 0110 1000 1001 1000 0000 |
| (>>>16)无符号右移16位 | 29830 | 000 0000 0000 0000 0111 0100 1000 0110 |
| ^(异或)运算 | 1955003654 | 111 0100 1000 0110 1111 1101 0000 0110 |
| 2^4-1=15(length-1) | 15 | 000 0000 0000 0000 0000 0000 0000 1111 |
| &(与)运算 | 6 | 000 0000 0000 0000 0000 0000 0000 0110 |
可以看到 “扰动” 之后,高低位互换后,就能极大的减少碰撞
哈希桶数组如何扩容
这里直接讲 JDK8的扩容方法
前面说过,这个 table 默认才分配 16个位置,随着元素的增加,这明显不够
看 JDK8的 put方法,它会在大于临界值时执行 resize 方法扩容,这个临界值默认是 0.75f,即当元素大于这个数据的 75% 时执行扩容方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
/* ... */
// 大于临界值
if (++size > threshold)
// 将数组大小设置为原来的 2 倍,并将原先的数组中的元素放到新数组中
// 因为有链表,红黑树之类,因此还要调整他们
resize();
// 回调以允许 LinkedHashMap 后置操作
afterNodeInsertion(evict);
return null;
}
下面就直接来看这个扩容方法的源码(看注释)
// 初始化或者扩容之后元素调整
final Node<K,V>[] resize() {
// 获取旧元素数组的各种信息
Node<K,V>[] oldTab = table;
// 长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 扩容的临界值
int oldThr = threshold;
// 定义新数组的长度及扩容的临界值
int newCap, newThr = 0;
// 如果原 table 不为空
if (oldCap > 0) {
// 如果数组长度达到最大值,则修改临界值为 Integer.MAX_VALUE
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 下面就是扩容操作(2倍)
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// threshold 也变为二倍
newThr = oldThr << 1; // double threshold
}
// 原 table 为 0,表示要初始化数组
else if (oldThr > 0) // 初始容量设置为阈值(JDK8 里这个阈值是计算过的,一般默认是 16)
newCap = oldThr;
// threshold为 0,则使用默认值
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果临界值还为0,则设置临界值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 更新填充因子
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 调整数组大小之后,需要调整红黑树或者链表的指向
if (oldTab != null) {
// 遍历旧数组,将原有 Node数组的元素拷贝到新的 Node数组里
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 重新计算元素在新数组中的位置
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 红黑树调整
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 链表调整
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
TODO: 扩容细节之后再补充
HashTable
如果不需要线程安全的实现,建议使用 HashMap 代替代码 Hashtable。如果需要线程安全的高并发实现,那么建议使用 ConcurrentHashMap 代替 HashTable。
Hashtable 是继承的 Dictionary 类,实现了 Map
Hashtable<Integer,String> hashtable = new Hashtable<>();
hashtable.put(1,"aa");
hashtable.put(4,"dd");
hashtable.put(2,"bb");
hashtable.put(3,"cc");
System.out.println(hashtable);
HashTable 和 HashMap 的区别
1、HashTable 继承于比较古老的 Dictionary,而 HashMap 继承自 AbstractMap 抽象类。
2、HashMap 是 HashTable 的一个轻量级实现,HashMap 不是线程安全的,而 HashTable 是线程安全的。
3、HashMap 允许 key 或者 value 为 null,而 HashTable 是不允许的。
4、HashMap 使用Iterator,Hashtable 使用Enumeration。
5、在效率方面:HashMap 的效率略过于 HashTable。不过 HashMap 和 Hashtable 采用的 hash/rehash 算法都几乎一样,所以性能不会有很大的差异。
6、Hashtable 和 HashMap 它们两个内部实现方式的数组的初始大小和扩容的方式不同。HashMap 和 Hashtable 的初始容量都是 16,负载因子是 0.75。但是扩容机制不同, HashMap 是旧数组的 2 旧表长度(一定是 2 的倍数),而 Hashtable 是 2 旧表长度 + 12 * 旧表长度+1 。
7、hash 值的使用不同,Hashtable 直接使用对象的 hashCode。而 HashMap 重新计算 hash 值。
如何使 HashMap 线程安全?
我们都知道。HashMap 是非线程安全的(非同步的)。那么怎么才能让 HashMap 变成线程安全的呢?
synchronizedMap 是一个方法,HashMap 本身非线程安全的,但是当使用 Collections.synchronizedMap(new HashMap()) 进行包装后就返回一个线程安全的 Map。
点进这个 synchronizedMap 方法内部,可以发现它创建了一个 SynchronizedMap 对象
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
来看 SynchronizedMap 的主要方法
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
从源码可以看出,SynchronizedMap 实现线程安全的方法也是比较简单的,所有方法都是先对锁对象 mutex 上锁,然后再直接调用 Map 类型成员变量 m 的相关方法。
这样一来,线程在执行方法时,只有先获得了 mutex 的锁才能对 m 进行操作。因此,跟 Hashtable 一样,在同一个时间点,只能有一个线程对 SynchronizedMap 对象进行操作,虽然保证了线程安全,却导致了性能低下。
它最大的好处就是传入的是一个 Map 接口,而不是具体的实现类,所以像 TreeMap 这种 Map 实现类就可以通过这个方法来生成一个线程安全的 Map
synchronizedMap(Map) 和 ConcurrentHashMap 区别 ?
ConcurrentHashMap 是 Java 1.5 中 Hashtable 的替代品,是并发包的一部分。使用 ConcurrentHashMap,不仅可以在并发多线程环境中安全地使用它,而且还提供比 Hashtable 和 synchronizedMap 更好的性能。
但是对于没有给出线程安全却需要线程安全的 Map 实现类就可以使用 synchronizedMap(Map) 来创建了
除此之外还有其它的并发工具,但是它们工作原理都是大同小异的
synchronizedCollection(Collection<T> c) //返回指定 collection 支持的同步(线程安全的)collection。
synchronizedList(List<T> list)//返回指定列表支持的同步(线程安全的)List。
synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(线程安全的)Map。
synchronizedSet(Set<T> s) //返回指定 set 支持的同步(线程安全的)set。
为什么不使用跳跃表
Skip List--跳表(全网最详细的跳表文章没有之一) HashMap为什么用红黑树而不用跳表?redis的zset为什么用跳表而不用红黑树?
Reference
参考资料 HashMap? ConcurrentHashMap? 相信看完这篇没人能难住你! 参考资料 HashMap 实现原理及源码分析 参考资料 JDK 源码中 HashMap 的 hash 方法原理是什么? - 胖君的回答 参考资料 使用位操作(&运算)代替求余操作 参考资料 HashMap中确定数组位置为什么要用hash进行扰动 参考资料 Java面试——HashCode的作用原理和实例解析